


Unlocking Your Company’s AI Future: Projects to Invest In Today Part 1
Generative AI and First Party Proprietary Data Collection

A competitive advantage emerges when everyone is able to ask the question but you are the sole possessor of the answer.
I want to start with two ideas that have fundamentally changed the way I think about the future of data team value creation & strategy:
Generative AI has forever changed the data & analytics landscape. Clever analysis & growth strategies are becoming commoditized and freely available and will continue to do so at a rapid pace. [1] [2]
The business value and benefits derived from generative AI will be concentrated among companies that establish and manage proprietary data sets, which can be analyzed for distinct insights that provide a competitive edge.
Building Proprietary Data Sets
Leveraging AI on top of proprietary data sets has gotten a lot of attention in the past few months and the most common examples given are pharmaceutical companies sitting on a treasure trove of private research data. What I think has been glossed over is the fact that every company can (and needs to) produce their own proprietary data set. For many non-research based businesses (especially SaaS and E-commerce) this means collecting customer behavioral data. In the past this required extra engineering investment and was reserved for later stage companies. However, the newer tools that are available make it a time saving project as the company grows and has to integrate/replace CRM’s, billing systems, communication platforms, etc that all get to share the benefit of first party data collection platform in place with pre-built connectors for all the common tools.
Behavioral data is the key to unlocking the most valuable analyses and models that companies can build including:
Acquisition funnel efficiency bottleneck analysis
Paid conversion drivers/correlations
Customer retention drivers/correlations
The cost of running and iterating on these analyses has significantly decreased due to generative AI tools, such as code interpreter, with more advancements expected shortly. Tracking the right things at a company has always been incredibly valuable, yet it is a rarely discussed topic, often relegated to product and engineering managers.
Historically lessons around missing behavioral data were learned slowly over time by founders asking hard questions but not being able to find answers. I would argue that the next batch of companies will need to learn these lessons earlier to stay competitive. The importance of having a data tracking strategy is becoming elevated to the level of existential imperative for companies today.
I’d like to offer a series of tips to speed up this process, embed best practices into the company’s DNA and put it on a path to data and AI success.
Part 1: Implement First Party Event Collection on Websites and Products the Company Owns
You'll never recover the behavioral data you forgot to collect.
Customer behavioral data is unique among the many types of data a company can generate.
CRM’s with missing customer information can be filled in with Clearbit/Zoominfo or surveys if the right properties were never collected
Billing/accounting systems can be audited and inferred based on transaction history at a later date
Support tickets can be re-tagged and cataloged for analysis at any time
But behavioral data that wasn’t collected can’t be recovered at a later point in time. It's a combination of the exact interaction of market forces and the company's product-market fit at that point in time and won’t be repeated. The value of behavioral data also increases over time, as having a more extensive historical record enables a company to more easily forecast and proactively respond to recurring user trends, such as seasonality.
Companies lacking these frameworks will face difficulties in implementing high-precision growth strategies like:
Product-Led Growth
Conversion Rate Optimization
Growth Engineering
On the surface, these organizations may initially appear similar to those with extensive behavioral data catalogs. However, over time, their paths will diverge as the compounded exponential benefits of small behavioral wins accumulate and positively impact the latter group.
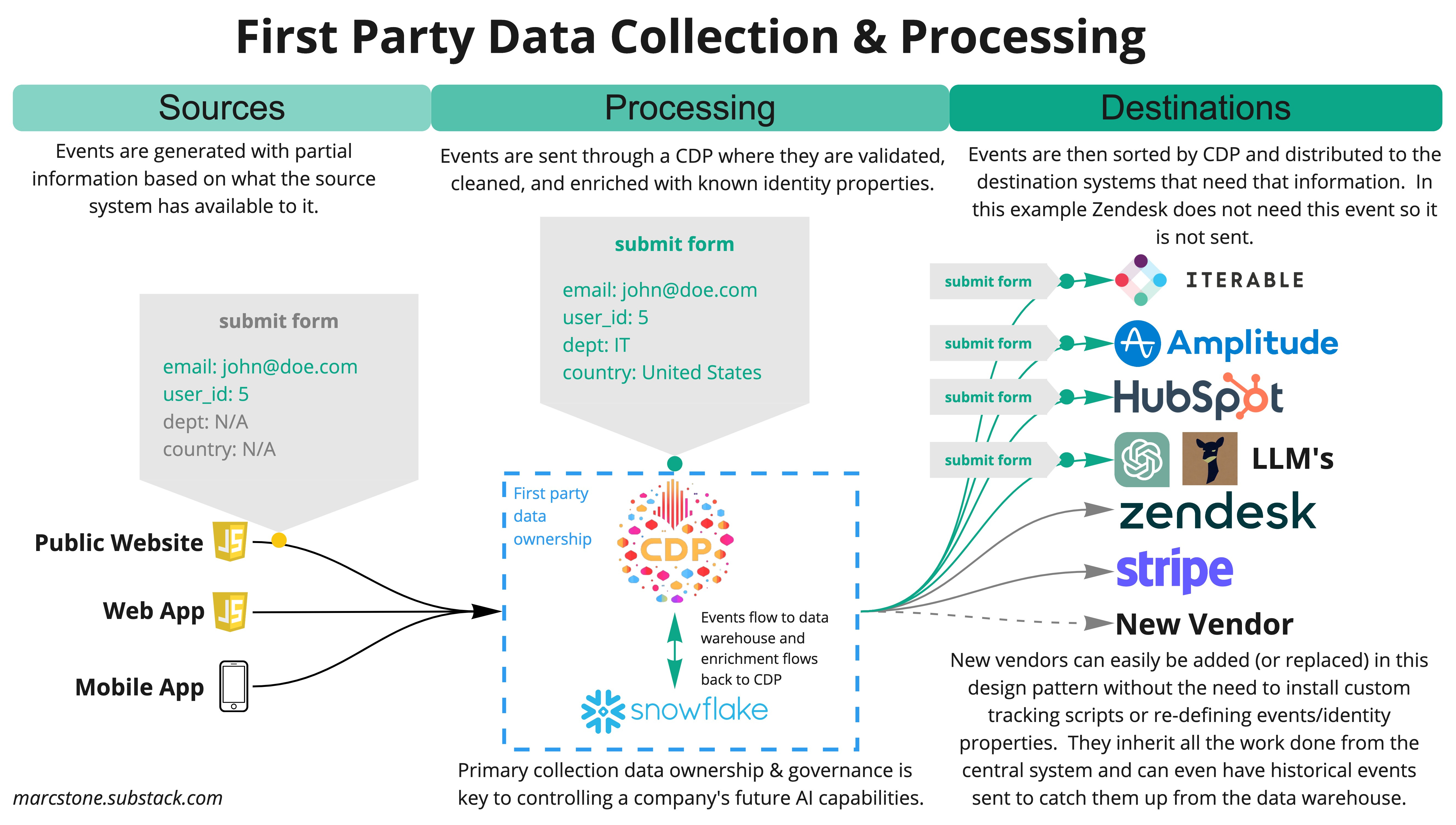
By utilizing tools commonly known as Customer Data Platforms (CDP’s), such as Rudderstack or Snowplow, companies can collect, clean, enrich, and store highly detailed data on user interactions. This information aids in making informed decisions, optimizing user experiences, and driving growth. A significant advantage of this project is that, once the tracking SDKs are installed on the website and product, no additional SDKs are needed for future tool or system integrations. Instead, teams can connect to the CDP and access the existing data stream for shared, consistent data, saving more time as the company expands.
Benefits to Implementing First-Party Event Tracking
Ownership of data: Collecting first-party data allows for full control and ownership, preventing vendor lock-in, enabling switches between analytics platforms (Amplitude/Mixpanel), and maintaining greater negotiating power with third-party vendors.
Simplicity of upgrading data stack: Once events are being cleanly generated in a single CDP type system adding new analytics, customer facing, or AI systems on top of a company’s data is greatly simplified. Usually as easy as flipping a switch and letting events flow in or even better, connecting to the data warehouse that holds months or years worth of historical data that can all be processed as well. If this isn't in place, the business will have to start from scratch with each new system added.
Data accuracy: First-party data is more accurate, as it is collected directly from users' interactions with the website and product. This reduces the risk of relying on potentially outdated or incomplete third-party data.
Personalization: First-party event tracking enables companies to create personalized user experiences by understanding individual preferences and behaviors across all platforms rather than a single collection vendor. This leads to increased user engagement, conversion rates, and customer loyalty.
Implementing Behavioral Event Collection
Some examples of platforms to check out would be Rudderstack, Snowplow, mParticle, Segment, and Tealium. Each offers different levels of free, open-source, and hosted solutions. Some use a warehouse first approach (my favorite) and others offer data redundancy and backup on their side. Some are better for B2C/E-commerce, while others are suited for B2B/SaaS. Here are some steps to get started:
Integrate the platform's SDK into the website and/or product to start collecting data on user form submissions, logins, and pageviews.
Set up a data pipeline to send the collected data to the data warehouse, where it can be stored and analyzed.
Monitor, analyze, and upgrade the tracking setup to ensure it’s capturing the right data and the company is making the most of it.
The time it takes to implement first-party event tracking varies depending on a company's size, technical expertise, and the complexity of its website or product. Companies shouldn’t try to “boil the ocean” here and can start with just the identify and pageview methods.
For small startups, it should only take a few days, while larger companies may require a few weeks to set up and refine their event tracking infrastructure. The key is to start as early as possible to ensure valuable data is captured from the outset, building a solid foundation for the company's data-driven future.
Additional Tips:
Relying solely on Google Analytics for website data collection is not recommended due to its limitations in data sharing and user identification. These constraints impede high resolution behavioral data usage because it is harder to get the data out and join it to other systems. While easy to use and beneficial when set up correctly, should serve as just one element of a larger website data collection strategy.
Don’t install or use third party vendor specific tracking SDK’s on the company’s website or apps. Instead utilize a direct CDP or warehouse connection for sending data to vendors. This prevents vendor lock in and allows the company to clean/process their own data before sending it off. There are a couple exceptions here where third party scripts perform functions that raw data sharing can’t, but this should be used sparingly to keep the company agile.
As a startup scales and is ready to invest (time) in improving data quality, Google Server Side Tag Manager is also an exciting technology that offers a rich set of data collection techniques that prevents a lot of the client side tracking data loss that is common.
Check out part 2 on user identification now! Have any thoughts or feedback? Find me on LinkedIn!